Methodology Hub
Climatiq is a carbon calculation solution. We provide the largest database of verified emission factors and an AI-powered carbon calculation engine for performing emission calculations across scopes 1, 2, and 3, including advanced use cases such as freight shipping, purchased goods and services, market- and location-based energy, and travel.
We uphold rigorous standards to ensure our data is reliable and our calculation methodology meets the requirements for compliant greenhouse gas (GHG) emissions measurements.
Our Scientific Advisory Board (SAB) is composed of experts across carbon accounting, climate science, ecological economics, and data science. We consult with our SAB for reviews, updates, and new feature releases.
Verification
Climatiq's product carbon footprint methodology, and calculations for energy, procurement (scope 3.1), freight, and travel, have been audited and verified to meet the requirements of ISO 14067, the GHG Protocol, and ISO 14064-3:2020-05. Our freight emissions methodology is accredited by the Smart Freight Center for GLEC-compliant calculations.
This ensures our data and calculations provide a verifiable, audit-ready basis for product-level carbon footprint reporting and disclosure that is recognized across voluntary frameworks, including CDP and the GHG Product Protocol Standard, and aligned with the LCA methodology underpinning emerging EU product regulations such as PEF, ESPR, and DPP. Calculations using Climatiq's tools can be used for reporting under regulations and standards requiring GHG Protocol compliance, for example CSRD / ESRS and IFRS, and region-specific reporting requirements such as NGER (Australia).
Our ISO 14067 audit covers the calculation methodology used by our PCF tools, ensuring industry standard frameworks are applied so that outputs are transparent and can be verified and replicated by third parties. To get ISO 14067 verified, auditors review and ensure conformance across key areas:
- Life cycle stages: All relevant cradle-to-gate life cycle phases must be accounted for, from resource extraction and upstream transportation to manufacturing, and emissions must be attributed to the appropriate stage
- Data quality: The time, geography, and technological applicability of data must be assessed and indicated through data quality indicators
- Transparency and data traceability: Methodology reports are verified to make sure they provide a comprehensive summary of assumptions and results are checked to ensure they are reproducible, with a full audit trail of emission factors used
- Calculations and conversions: All greenhouse gases must be quantified and converted into CO2e, and results should include biogenic carbon when data is available
Verification of an individual PCF is a separate exercise and remains the customer’s responsibility, with Climatiq providing a verified, documented methodology as the base. Calculation audit trails and data lineage means you can take PCF results calculated in PCF Studio to an auditor with confidence.
Climatiq also holds certifications for ISO 27001:2017 and SOC 2 Type II, demonstrating adherence to high standards for information security and data privacy. Additionally, regular penetration testing is conducted, with reports available for review.
You can find our assurance certificates and audit reports here.
Data methodology
Our emission factor database is the largest of its kind. We integrate data from a range of sources such as governmental bodies, not-for-profit organizations (NGOs), and academic institutions to cover 300 regions, all scopes, and spend- and activity-based data.
Before ingression, new data undergoes a rigorous vetting process to ensure quality and reliability. It is then normalized to fit with our self-developed data schema.
Data coverage
Sources of emission factor data
Climatiq offers the largest emission factor database. We include data from more than 60 sources and 140 datasets, including governmental bodies such as EPA in the United States and BEIS / DEFRA in the United Kingdom, and other verified providers such as NGOs, ecoinvent, and IEA. Discover the data sources we cover here.
Below is an interactive visualization of the datasets in our database.
Regional coverage
Our emission factors cover 300+ global regions, ranging from countries to local regions and cities. While some regions are more comprehensively represented than others, our database also includes data for underrepresented areas, ensuring broad and diverse geographic coverage.
Types of emission factors
Our data covers tens of thousands of activities. We define activities as processes covered by emission factor data. This includes (but is not limited to) activities in energy covering electricity, fuel, cooling, and heat and steam; transport services and warehousing; consumer goods and services such as clothing, food and beverages, furnishings, and health care; materials and manufacturing products such as ceramics and clay, and many others.
The emission factors in the Climatiq database cover a broad range of units to accommodate for the largest selection of measurements possible across activities. This includes area, distance, energy, money, time, volume, and weight units.
The Climatiq database provides both activity-based and spend-based emission factors to ensure comprehensive coverage and applicability across various use cases.
Emission scopes
The database includes direct (scope 1), indirect (scope 2), and value chain (scope 3) data, including upstream and downstream emissions, to offer a fully rounded insight into a company’s footprint. All emission factors in the database will soon be categorized according to their appropriate scope. This facilitates compliance-ready reporting for evolving regulatory requirements such as CBAM.
Data updates & corrections
We release regular updates to our emission factor database, usually on a monthly basis. Each release consists of additions, deletions and updates. These releases are necessary when a source publishes errata, new data quality flags are applied to existing emission factors, or when changes are made to a factor's metadata, for example.
Updates like these often require changes in user applications. Therefore, we use the concept of data versioning, which allows users to choose when to opt-in to such changes, providing greater control over emission factors and data quality used in their calculations.
These updates ensure consistency and reproducibility in emissions calculations and ensure the database remains accurate and up-to-date.
New datasets are documented in our product release notes.
Data quality
We ensure all our data is compliant with the requirements of the GHG Protocol through:
- Vetted data sources: Climatiq uses vetted datasets sourced from leading government agencies and trusted global organizations.
- Coverage: Our emission factors span multiple industries, activities, and geographies, ensuring relevance for diverse use cases.
- Transparency: All methodologies, data sources, and assumptions are fully documented and accessible to our users, ensuring transparency.
- Open data: We provide detailed references for every emission factor, allowing users to trace data back to the source.
- Up-to-date data: Our platform continuously integrates updated emission factor datasets, following the latest regulations.
- Uncertainty: When provided by the source, Climatiq displays the level of uncertainty associated with each emission factor.
- Scopes: All emission factors in our database are categorized according to their appropriate scope to support scope-specific calculations.
As we only include data from trusted publishers, emission factors from Climatiq’s database can be used for reporting under local and international regulations and standards that require GHG Protocol compliance.
Traceable to source
All data provided by Climatiq is linked back to the original source and enriched with metadata such as validity year, source, CO2e calculation method, region, quality flags and LCA activity. Our goal is to make it as easy as possible to verify the origin of all data in our database.
Quality assurance
Climatiq ensures users are informed about data quality through a robust flagging system that highlights potential issues, such as methodological ambiguities, partial emission factors, or outliers. This approach empowers users to make confident and informed decisions about the emission factors they use, while eliminating the need for them to conduct their own quality assessments.
Below is an outline of our quality assurance process:
- Every new data point undergoes automated validation checks to identify inconsistencies, missing values, zero values, or misalignments with expected ranges.
- We use machine learning algorithms to detect outliers and flag unusual values to alert users for data anomalies.
- Emission factors for the same activity but sourced from different datasets are compared to ensure consistency and agreement, checking if there are any erroneous values.
- We assess the IPCC Assessment Report (AR) calculation methods used by each source in calculating emissions.
- We review the life cycle assessment (LCA) boundaries and ensure that the appropriate scope (1, 2, or 3) is applied to the data.
- If a source provides only partial information (e.g. only CO2 emissions without other GHGs), we explicitly mark the data as partial to maintain transparency and inform users of its limitations.
- After passing automated checks, the data is reviewed by our Science and Data team, which includes PhD-educated scientists and carbon accounting experts.
- This manual review ensures that any issues—such as methodological limitations or data gaps—are addressed, adding a further layer of review that automated systems may overlook.
- We continuously refine our QA processes based on user feedback, new sources, and changes in regulation standards.
Our data vetting and ingestion process at a glance:

Uncertainties and data gaps
Our emission factor values typically don’t come with uncertainties because most sources do not report them. While Climatiq covers many sources, only ADEME (the French Agency for Ecological Transition) explicitly provides uncertainty values. We understand that users value this information, but its absence reflects a broader challenge in carbon accounting practices and data reporting across the majority of sources.
Our dedicated Science and Data team works continuously to identify new sources and expand coverage, actively filling data gaps to enhance the database over time.
Public access
The Climatiq Data Explorer provides an easy-to-use interface to browse, review and verify the accuracy and reliability of the data provided.
By offering free access to the database, we also empower businesses across the globe to start assessing their environmental impact with reliable data.
Data schema for emission factors
The Climatiq Emission Factor Database offers a novel solution to the challenge of emission factor standardization. By harmonizing scientifically vetted emission factors into a cohesive schema, we provide a reliable resource that makes it easy to compare emission factors across a variety of sources, sectors, and regions.
Normalization
The process of normalizing emission factors ensures that factors from different datasets and for different regions are comparable, by adjusting or removing variables that could otherwise skew the data.
Key features of our schema and normalization process:
- Emission factors are classified by sector, category and region, making it simple to search and compare data across industries, activities, and geographies.
- Year information is clearly specified, distinguishing between the year of publication and the year for which the data is applicable, which can sometimes differ.
- Activity units are consistent (e.g. kgCO2e per activity unit) to eliminate confusion and variability stemming from differing units across datasets.
- We report the IPCC Assessment Report (AR4, AR5, or AR6) calculation method used, as provided by the source, to maintain transparency.
- LCA activity and scope are reported to clearly define boundaries and applications.
- Descriptions provide detailed context about the data’s origins, assumptions, and methodologies, offering users a deeper understanding of the factors.
- Source links ensure traceability, enabling users to easily trace back to the original dataset.
- The data quality field allows us to report potential issues, such as partial factors, methodological variances, erroneous calculations, or suspicious outliers, ensuring the user is aware of the quality of each emission factor.
- The schema is dynamic and evolves to incorporate new datasets with new methodologies, as well as regulatory updates, ensuring the database remains up-to-date and comprehensive.
- We standardize emission factor values by converting all data in the database to kilograms of CO2e for each greenhouse gas (carbon dioxide, methane, and nitrous oxide). This ensures the data accurately reflects the specific impact of each gas and enables precise calculations of CO2e.
Our schema is illustrated in the table below using a 2023 ‘LPG tanker’ emission factor provided by BEIS as an example. The first column lists the individual properties of the Climatiq schema.
Emission factor modeling
Climatiq’s database includes thousands of emission factors from many sources. In most cases, these cover what is needed for emissions calculations. Where there are specific data gaps or our customers require tailored calculations, we've developed Climatiq Composite emission factors.
The Climatiq Composite emission factors cover:
- Spend-based: These emission factors are derived from the UK Government spend-based factors and are adjusted for inflation and trade margins;
- Material use: These are weighted averages of the UK Government emission factors for material use based on typical market share of the production methods;
- Commuting: Emissions from a typical day’s commute for different UK regions.
Climatiq Composite spend-based factors
Spend-based factors are typically used to estimate emissions from purchased goods and services (GHG Protocol scope 3.1) and capital goods (scope 3.2).
Climatiq’s spend-based emission factors are based on the UK Government dataset “UK and England's carbon footprint”. The source uses Environmentally Extended Input-Output (EEIO) tables that link monetary value added by each industry with associated emissions.
The Climatiq team has adjusted the factors for inflation and from basic to purchaser prices. These adjustments are similar to those made in the procurement endpoint.
The description for each emission factor contains the inflation and price adjustment values used. For example:
Emission intensity of supply chain adjusted from basic to purchaser prices and adjusted for inflation. Based on the UK Government "UK and England's carbon footprint to 2022". Purchaser price adjustment taken from UK ONS "Input-output supply and use tables". Inflation adjustments taken from ONS Producer / Supplier and Construction Price Indices. Original CO2e value: 0.2. Basic to purchaser price multiplier: 0.99. Price index (inflation) multiplier: 0.97.
Inflation adjustment
The UK Government factors are three years behind the publication year—factors published in 2025 use 2022 prices. It is therefore usual to apply an inflation adjustment. We do this by using annual price indices, which are available for 2022, 2023, and 2024. As the latest emission factors use 2022 prices, we adjusted for inflation for 2023 and 2024.
Adjustment to purchaser prices
For spend-based calculations, it is best practice to adjust basic prices to purchaser prices. Purchaser prices include distributors’ (wholesale and retail) margins and the net impact of government taxes and subsidies.
Climatiq Composite average material use factors
The UK Government publishes up to three different emission factors for any given material, one for each source: primary material production, re-used, and closed-loop source.
Climatiq has created a weighted average for an “average source” for each material based on its market share. Market share is estimated based on data from credible sources. Where there is no credible market share data, or where we know the secondary market share is minimal, we make simplifying assumptions.
Climatiq Composite commuting factors
Climatiq has created emission factors for an average commute in different regions of the UK using publicly available data. These are intended to give a first, screening-level estimate of commuting emissions where no other data is available.
The emission factors represent one day’s two-way commute including upstream emissions from fuel production. They are derived from UK Government data.
Product carbon footprint (PCF) emissions calculations
Climatiq's product carbon footprint (PCF) tools automate cradle-to-gate and cradle-to-grave emissions calculations for physical products, in conformance with ISO 14067 and the GHG Protocol Product Life Cycle Accounting and Reporting Standard. Climatiq provides two PCF products: PCF Studio and the PCF API.
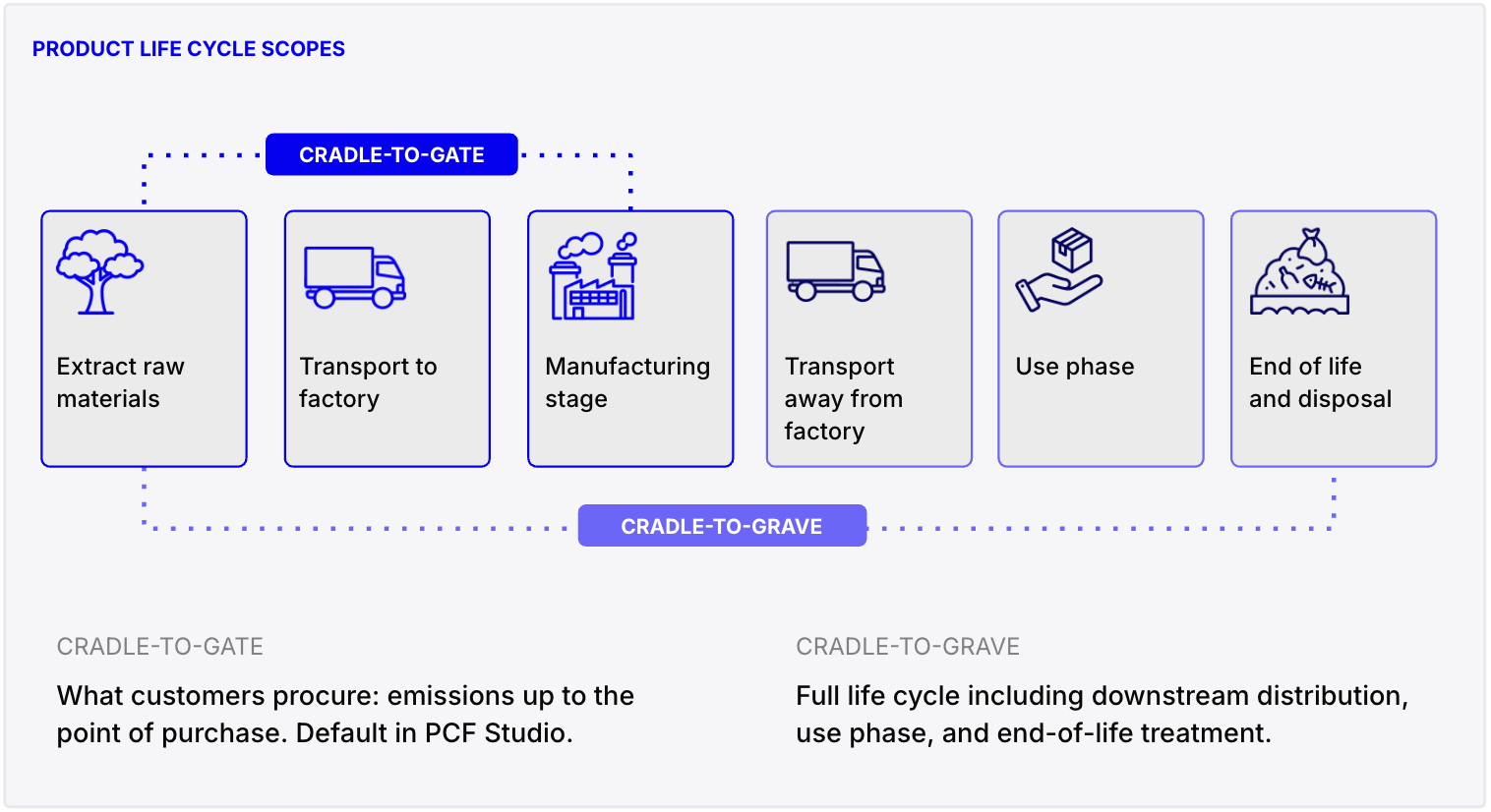
System boundaries
System boundaries define which life cycle phases, processes, and activities are included in or excluded from a life cycle assessment. PCF Studio supports cradle-to-gate calculations, while the PCF API also has the option to do cradle-to-grave assessments:
- Cradle-to-gate: Raw material extraction through manufacturing, before the product leaves the factory
- Cradle-to-grave: The full life cycle, including use phase and end-of-life. Gives the most complete picture but requires more data and modeling assumptions
Data sources
Climatiq’s PCF calculations draw on scientifically-verified datasets from our emission factor database, including Agribalyse, Circular Ecology, and Plastics Europe, as well as premium databases like ecoinvent, IEA, and Carbon Minds.
Only datasets with appropriate lifecycle boundaries for product carbon footprinting are included. Please refer to the dataset pages and source documentation to find the specific boundaries of individual emission factors used.
If users have access to primary data from their suppliers, they can specify custom factors to use in PCF calculations.
Materials and components
Bill of materials
A bill of materials (BoM) is a structured list of all components, sub-assemblies, raw materials, and the associated quantities in a finished product. Climatiq uses the BoM as the primary input for a PCF. We map each line item from the BoM to an emission factor from our vetted emission factor database using Mapping Agent.
Emission factor selection
Mapping Agent uses a proprietary AI model to help users find a matching emission factor for their components and materials. Read more under Mapping Agent.
The mapping algorithm selects only emission factors with appropriate lifecycle boundaries for product carbon footprinting. For each line item, the user has full transparency into the mapped emission factor and its methodological details, and is able to swap the factor for another one from our database. Inputs are supported in 47 languages.
Region and year fallback logic applies when emission factor data is unavailable for specific locations or time periods. The applied fallback is flagged in the tool.
The PCF API allows users to specify that a component is sourced from multiple suppliers or regions, in which case a weighted average of emissions is applied, which includes transport, components, packaging emissions, and more.
Data gap filling
If BoM data is missing, PCF Studio can use the product name to generate a probable list of components using AI. This offers a pragmatic approach to get a first impression of emissions, but users should take extra care to verify each component for accuracy based on the information they have and ideally replace with real data once it becomes available.
If weight data is missing from the BoM, PCF Studio can convert any other unit to weight, taking the component characteristics into account to create an estimate.
Upstream transport
Upstream transport emissions are calculated using Climatiq's GLEC-accredited freight calculation engine. The calculation determines multi-modal transportation routes heuristically based on the supplied component sourcing and manufacturing locations.
If a primary mode of transport is provided, the calculation will automatically identify and calculate the pre- and post-leg for the journey through automatic routing. If users don’t supply specific transport data, but have a start and end destination, Climatiq will determine a likely transportation mode automatically.
Based on the route, Climatiq will intelligently pick between sea transportation, which is the most common type of shipping, and road transportation for shorter routes. If Climatiq determines that sea shipping is the most likely transportation mode, but your locations are not close to sea ports, road legs will automatically be added to transport the cargo to the closest port.
Manufacturing
Emissions from the manufacturing step are captured through user-supplied or Climatiq-estimated process- or product-level energy inputs. Electricity, heat and steam, and fuel emission results are broken down into well-to-tank (WTT), transmission and distribution (T&D) losses, and well-to-tank of transmission and distribution losses (WTT of T&D).
Process-level vs product-level
Users of PCF Studio can choose how to input their data:
- Process-level: users can add energy used across individual manufacturing steps individually, for example from cutting, molding, or assembly, using process-level energy records
- Product-level: users can specify a combined total electricity, heat, steam, and fuel use across all manufacturing processes at the product level, using utility bills or annual reports
Electricity
Emissions from manufacturing electricity consumption are calculated using the market-based approach to ensure PACT (Partnership for Carbon Transparency) compliance. The methodology follows our Energy emission calculations approach. For premium IEA license holders, calculations use high-resolution regional factors. Users can select the energy source such as renewable, coal, natural gas, biomass, or nuclear, or source supplier-specific factors themselves. For the UK and US, Climatiq provides supplier-specific factors.
Heat and steam
Users can add heat and steam consumed during manufacturing, with the option to select the energy source or provide supplier-specific factors. Calculations follow the same methodology as the heat and steam endpoint of the Energy API.
Fuels
The user can also add fuel used in manufacturing by specifying the type and amount of fuel burned. Climatiq provides data for 200+ fuel types. The calculation automatically uses the manufacturing location and year, and follows the same methodology as the fuel endpoint of the Energy API.
Water
Users also have the option to add water inputs if data is available. This allows them to account for emissions from water treatment, for example.
Data gap filling
When energy inputs are missing, PCF Studio uses AI to ascertain the most typical processes involved in manufacturing the given product, and from that the typical electricity or fuel amount and types. The user can verify and edit the proposed processes, energy amounts, and fuel types so they maintain control over their inputs.
Use-phase
For cradle-to-grave estimates using the PCF API, the user has the option to incorporate use-phase emissions during the product’s lifetime. This can encompass things such as emissions emitted by installation and deinstallation processes or energy consumed during operation or stand-by. For energy usage, the calculation is performed using the market-based approach for PACT compliance following our Energy emissions calculation methodology.
End-of-life
The API calculates end-of-life emissions using material composition data derived from the input materials. When disposal-specific data is not provided, the API determines material composition from components and calculates emissions using the most common disposal methods for each material type. All material classifications and disposal assumptions are documented in the audit trail.
The API implements a cut-off allocation method, attributing only disposal emissions to the product, not recycling benefits.
Data quality indicators
Every calculation includes three data quality indicators aligned with the PACT standard, each rated 1 (best) to 5 (worst):
- Technological representativeness: Degree to which factors reflect actual technologies used
- Geographical representativeness: Degree to which factors reflect actual process locations
- Temporal representativeness: Degree to which factors reflect actual time period or data age
Scaled data quality indicators multiply each rating by the component's CO2e contribution, revealing which components most impact overall uncertainty. This helps users prioritize primary data collection efforts.
Current limitations
- Direct emissions from chemical reactions (such as cement calcination) are not calculated
Climatiq continuously expands PCF calculation capabilities based on user feedback and regulatory requirements.
Mapping Agent
Mapping Agent automatically matches unstructured text from purchase orders, Bills of Materials, or invoices to the closest emission factors across scopes 1, 2, and 3 using Climatiq’s proprietary NLP model. The user has the option to input descriptive text to improve accuracy of matching.
It matches emission factor(s) to text by assessing how similar two strings of text are based on their semantic meaning. We use ranking to assess relevancy. Our models are regularly fine-tuned on real-world data.
Mapping Agent API uses emission factor data from the entire Climatiq database (and ecoinvent, if included in the user’s package). All regions are covered. Depending on the emission factor availability, region fallbacks are implemented.
The response includes the CO2e estimate and details about the calculation. The user also receives a confidence score to indicate the reliability of the match.
Mapping Agent includes a Suggest feature that returns suggested emission factors for a particular calculation. The user can specify the number of suggestions to return. These are then ordered by the most likely match first.
The Estimate feature calculates total estimated emissions produced for an Mapping Agent-matched activity, in kgCO2e. Estimations can be performed with a suggested activity from the Suggest endpoint, or by using free-text input, which will automatically calculate emissions with the best emission factor match.
Emission calculation methodology
Our plug-and-play API automates complex carbon calculations, and has been used by our customers to power over 1.5 billion CO2 estimates. The API transforms activity data from various use cases such as energy consumption or freight shipments into emissions estimates. It automatically selects the most fitting emission factor using AI, and then applies the necessary calculation logic to work out a CO2e estimate.
Our team of climate scientists generally develops the calculation logic in-house, which is then reviewed and certified by third parties such as the Smart Freight Center to ensure reliability.
To address gaps in our data, our API applies a region fallback logic to identify the most relevant emission factor when data for a specific area is unavailable. Similarly, we use a year fallback logic to account for missing data from specific time periods, ensuring users receive the closest applicable emission factors.
ERP platforms, supply chain management platforms, and ESG solutions can then integrate Climatiq’s API into their own software to provide their customers with emissions estimates across a range of activities.
Energy emission calculations
Our energy API gives access to built-in logic for scope 1 fuel combustion, scope 2 location- and market-based electricity, and upstream scope 3.3 fuel and energy-related activity (FERA) calculations. The energy endpoint automatically calculates the greenhouse gas emissions from the energy consumed by using relevant emission factors. Where emission factors for particular regions are not available, the endpoint uses Climatiq’s advanced calculation methodology to estimate emissions, thus helping reduce gaps in reporting.
Drawing on data from the International Energy Agency (IEA), Association of Issuing Bodies (AIB), Environmental Protection Agency (EPA) and more, users input region, quantity of energy consumed, and year (optional) to receive emission insights.
For more advanced users, Climatiq includes emission factors specific to electricity suppliers in several countries. Users are also able to specify their own supply-specific factors or fuel mix if they have the data available.
The API provides results for location-based and market-based approaches. We offer support for all fuel types and 19 input units, auto-allocation of renewable energy certificates (RECs), and coverage for heat and steam, well-to-tank (WTT), transmission & distribution (T&D), and WTT of T&D. Over 120 global regions are covered, with state or sub-grid coverage across the US, Canada, and Australia.
Freight emission calculations
Climatiq’s freight API has Smart Freight Centre Accreditation, which ensures its calculations align with the GLEC framework.
All emission factors used are from the Global Logistics Emissions Council (GLEC) framework, except for grid electricity factors for powering electric vehicles from the International Energy Agency (IEA). Routing between start and end location is done via OpenStreetMap (rail), HereMaps (road), Eurostat (sea) and Great Circle Distance method (air).
The GLEC Framework follows international standard ISO 14083 and is recognized by major carbon accounting and reporting organisations (GHG Protocol, CDP, SBTi).
The user must supply the weight of cargo and the start and end destination of the shipment or a distance. They may also add multiple journey legs—up to three by default with the option to request more. The API then automatically selects emission factors for the regions, vehicles, and load from GLEC. It calculates the distance between the start and end location of the shipment, and finds the logistics hub (port, railway terminal, or airport) that is closest to those locations. In the case that there is no logistics hub within the specified radius, the user must add another leg to account for inland travel. Users may specify region, fuel type, size, or load type to increase precision.
In the case of missing or partial address information, there is resolution logic for addresses, including geocode, partial/full street addresses, ZIP/postal codes, UN-Locodes, or IATA airport codes.
For air travel, a distance uplift is applied to account for maneuvering in accordance with the EN16258 methodology requirements, usually 95km per leg. The estimate is also multiplied by a Radiative Forcing Index of 2 to account for the fact that greenhouse gasses emitted at higher altitudes contribute more to global warming.
Users are supplied with a source trail detailing all emission factors used in the calculation.
Travel emission calculations
The API calculates emissions from air, train, and car (including taxi) travel globally, as well as hotel stays, to cover emissions under scope 3.6: business travel. Spend-based and activity-based approaches are supported. It uses logic developed by Climatiq, taking into account upstream and use-phase emissions.
Air travel
The air travel endpoint calculates flying emissions based on emission factors from the UK Government. The UK Government's datasets are especially well-regarded and widely used around the world; other providers, such as the EPA and GHG Protocol, often publish emission factors sourced from UK datasets rather than calculating their own. The UK Government has a nuanced methodology for calculating air travel emissions that incorporates a multitude of factors such as fuel type, cargo weight, distance traveled, and ground operations.
The endpoint automatically applies a Radiative Forcing Index of 2, which is used to account for the increased environmental impact of fuel burn at high altitudes.
The endpoint factors haul type (domestic, short haul, or long haul), cabin class (optional) and year (optional) into its calculations.
Car journeys
For cars with unspecified or unknown fuel types, the car travel endpoint uses the average factor from the UK Government, except in the USA where the EPA provides a specific average car factor.
Estimations are based on powertrain, car size, and distance traveled. The endpoint considers a range of car types (e.g. diesel, petrol, electric, etc.).
Train journeys
For the UK and US, the endpoint uses the train travel emission factors from the UK Government and EPA respectively, which account for the level of electrification within those countries. For other countries where national factors are not available, emissions will be calculated as a weighted average between electric and diesel train travel, based on the country's rail electrification rate.
Estimates are based on distance and electrification rates of the specified country. The train travel endpoint uses a routing algorithm through rail networks. We do not have full coverage of the global rail network. If data on specific rail segments is missing, we may use car routes for distance calculations.
Hotel accommodation
For hotel stays, the API can use activity- and spend-based data, drawing on the UK Government and EXIOBASE datasets respectively depending on whether calculating by nights stayed or cost of stay in the given region.
In cases where the region of interest is not covered by the UK Government or EXIOBASE, a fallback logic is applied using median values.
Procurement emission (spend-based) calculations
Spend-based emission calculations are a common way to estimate emissions for purchased goods and services (GHG Protocol category 3.1) when detailed activity data is not available. The Environmentally-Extended Input-Output Model EXIOBASE is the most commonly used resource for spend-based emission factors.
The API streamlines the calculation of carbon footprint for purchased goods and services by automatically deriving basic (factory-gate) prices, which are necessary for EXIOBASE calculations.
If the expenditure occurred in a different year than the emission factor's year, the expenditure amount has to be adjusted to match that emission factor's year. This requires taking into account both inflation adjustment and exchange rate fluctuations to arrive at the adjusted spend amount. The procurement endpoint automatically corrects for currency exchange rates and inflation adjustments, using rates from the UN Treasury, the IRS and the World Bank, supplemented with per-industry inflation numbers from Eurostat.
The endpoint provides the flexibility to provide your own margin rates in the API query, or, if unknown, to default to margins derived from EXIOBASE.
For the development of the Procurement endpoint, we collaborated with Prof. Richard Wood, a key developer of EXIOBASE. Prof. Wood is a member of our scientific advisory board.
Audit trails
Audit trails provide detailed information about the emission factors used in calculations for advanced endpoints such as freight shipping and classification. They can be stored with calculated emissions for future reference and audits.
All calculations include audit trails documenting:
- Emission factor name and unique identifier
- Source organization and dataset
- Year of validity and geographic region
- Lifecycle assessment boundary
- Data quality flags
For transportation, trails include calculated routes, logistics hubs, modes, and distances. This transparency supports third-party verification and regulatory reporting.


.svg)
